
A Summary for Vision-Language Transformers
Published:
In this post, I present the VL Transformers from its basic formulation to the recent progress that aims at improving its flexibility, efficiency and performance.

Picture from https://www.entefy.com/blog/post/584/entefy%E2%80%99s-quick-introduction-to-multimodal-ai-video
A Summary for Vision-Language (VL) Transformers
What is it?
Transformers are becoming the most popular architecture in both NLP and CV recently. For instance, on NLP there are BERT & GPT for language understanding, T5 for language generation and XLM for multi-lingual language representation, on CV there are ViT & Swin-T for general image representation and DETR for object detection. They usually require the inputs as a sequence of tokens. Specifically, this could be a set of image patches, CNN features or word embeddings. A class token $z$cls is prepended at front to represent the overall feature of the sequence and position embedding $P$ is added to indicate the position of tokens in the sequence. Thus the final input sequence can be written as:
\[z^0=[z_{cls}\quad EX_1 \quad ... \quad EX_T] + P\]where $E$ is the projection operator to align the original data to input token. And then layers of attention mechanism is applied to find connections between tokens.
\[y^l = \text{MSA}(\text{LN}(z^{l-1})) + z^{l-1} \\\\ \quad z^l = \text{MLP}(\text{LN}(y^l)) + y^l\]where MSA denotes the multi-head self-attention operation and LN is the layer norm. Finally, a task-specific head is applied on the CLS token of last layer to acquire the output. Note that these operations are exactly the same across modalities, and thus, a recent line of research tokenizes vision and language separately, and then concatenate them as inputs into a single transformer that performs self-attention across modalities.
Why Do We Need It?
Transfer Learning from Large Dataset
Designing task-specific architecture could be complicated and sometimes impossible since we don’t have enough data to train it. By pretraining a transformer on a large and often noisy dataset served for general purpose, we could acquire enough knowledge to easily transfer to a downstream task without changing architecture.
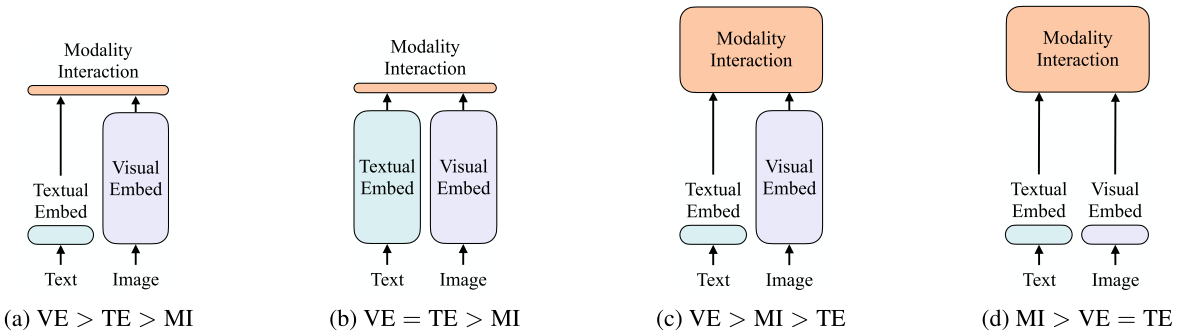
More Inter-modality Interaction
A fundamental problem of multi-modal learning is modality fusing. Self-attention layers could naturally bridge the two modalities by sharing the same key set between them. This also increases the inter-modality interaction as illustrated from Fig.1.
Some Pioneering Works
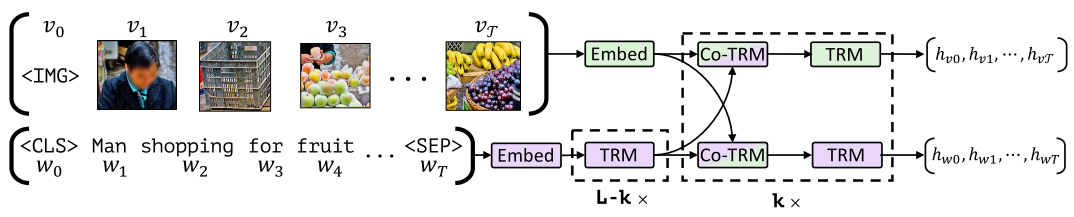
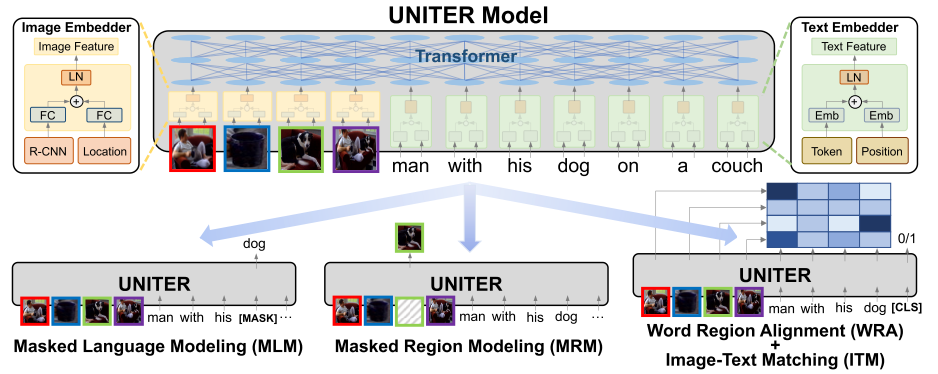
Most pioneering works are very similar and only have subtle differences on architecture and pretraining. Moreover, a recent work (Bugliarello et al. (2020)) points out that under the same hyperparameter setting, they perform on par with each other. And thus we only show ViLBERT and UNITER as an example in Fig.2 and Fig.3. We also make a summarize in Tab.1 that shows their differences in terms of architecture design, pretraining and downstream tasks according to the original paper. Notice that this is not a comprehensive list.
| model | year | streams | pretrain dataset | pretrain objectives | downstream task |
| ViLBERT | 2019 | two | CC | ITM, MLM, MRM-kl | VQA, VCR, REC, IR, zero-shot IR |
| LXMERT | 2019 | two | MS COCO, VG, VQA v2.0, GQA, VG-QA | ITM, MLM, MRM-reg, MRM-cls | VQA, GQA, NLVR |
| VisualBERT | 2019 | single | MS COCO | ITM, MLM | VQA, VCR, NLVR, Phrase Grounding |
| VLBERT | 2019 | single | CC, BooksCorpus, English Wikipedia | MLM, MLM (text only), MRM-cls | VQA, VCR, REC |
| UNITER | 2019 | single | MS COCO, VG, CC, SBU | ITM, MLM, MRM-kl, MRM-reg, WRA | VQA, VCR, NLVR, REC, IR, TR |
| InterBERT | 2020 | two | CC, MS COCO, SBU | ITM (hard negative), MLM (segment), MRM-cls (high intersection) | VCR, IR, zero-shot IR |
| Unified VLP | 2020 | single | CC | MLM, Seq2Seq | VQA, Caption |
| Unicoder-VL | 2020 | single | CC, SBU | ITM, MLM, MRM-cls | VCR, IR, TR, zero-shot IR, zero-shot TR |
| VILLA | 2020 | single | CC, MS COCO, VG, SBU | ITM, MLM, ITM-at, MLM-at | VQA, VCR, NLVR, SNLI-VE, REC, IR, TR |
| Oscar | 2020 | single | CC, MS COCO, SBU, GQA, Flickr30k | MLM, Contrastive | VQA, GQA, NLVR, IR, TR, Caption, NoCaps |
| VinVL | 2021 | single | CC, MS COCO, SBU, GQA, Flickr30k, VQA, VG-QA | MLM, Contrastive | VQA, GQA, NLVR, IR, TR, Caption, NoCaps |
[Tab.1]
For inputs, all the models in Tab.1 take RoI features from a pretrained object detector such as Faster-RCNN and project it as image tokens. Text tokens are the same as in BERT. Special tokens and position embeddings are also added in most models.
For architecture design, earilier works like ViLBERT and LXMERT favor two-stream encoder where the vision and language parts are encoded by separate encoders in the beginning, and then fused by a multi-modal encoder. They claim that by encoding them independently, it can preserve the unique characteristics of each modality. However, recent works prove that single stream architecture can also work well, such as VLBERT and UNITER. These models directly concatenate the vision and language tokens as input to a single transformer.
For pretraining datasets choice, four datasets are used the most: Conceptual Captions (CC), MS COCO, Visual Genome (VG) and SBU. Combining them into a larger pretraining dataset will generally lead to better results.
For pretraining objectives, there are usually Image-Text Matching (ITM), Masked Language Modeling (MLM) and Masked Region Modeling (MRM) similar to that in BERT. There is also Word Region Alignment (WRA) as proposed in UNITER. Furthermore, adversarial training is used in VILLA (Gan et al. (2020)) which boosts the performance.
For downstream tasks, VQA, VCR, Image Retrieval (IR), Text Retrieval (TR), NLVR, Referring Expressiong Comprehension (REC) and Captioning are the most popular ones. Vision-Language Tranformers achieve SOTA results in each of them compared to previous task-specific architectures, which I think mostly thanks to the pretraining-finetuning paradigm and the transformer encoder.
Problems and How to Improve It?
As you might have already noticed, there are several obvious drawbacks such as the use of an object detector. We summarize some more disadvantages in this section and we will also show some examples of how to improve it.
We will first list several problems about pioneering works.
Reliance on Object Detector
On one hand, it could be difficult to have an off-the-shelf object detector sometimes. Lets say we want to build a VL model for medical X-ray reports and there is almost no way we can get an object detector for organs or cancers for free. On the other hand, merely taking object regions as inputs remove all the necessary context information. For instance, as shown in Fig.4, current VL transformers take object bounding boxes as inputs which is the boat, the man and the woman, and there is no way for a model to infer whether the couples are sitting in the boat or on the shore. Another obvious defect is that object detectors are fixed-vocabulary, meaning that they can not handle objects unseen during pretraining, however, we could alwasy encounter long tail object classes in the open ended vision language interaction. And finally, we always have to perform one more inference with an object detection phase at first which makes it inefficient for real-world applications.

Fig.4 As shown by Huang et al. (2021), current vision-language transformers fail to consider the global information in the image. Learn from Paired Image and Text
These pioneering works always rely on paired image and text as training data, which prevents them from utilizing information from larger amount of independent images and texts. The curated caption datasets usually have simple and structured language which hinders the NLU ability for VL Transformers as shown in Iki et al. (2021). Moreover, these annotations could be noisy sometimes which makes pretrained models unreliable.
Can Multi-task Pretraining Help?
As shown by an early NLP work Liu et al. (2019), a simple multi-task training could benefit all the downstream tasks. A similar question could be asked for VL Transformers: Can multi-task learning benefit them?
How to Finetune?
How do we efficiently utilize these pretrained models for downstream tasks. Do we always need to prepare large amount of data for finetuning? Do we need to finetune all the parameters together?
Can We Do Image Generation from Them?
Notice that the pioneering works are never applied to an image generation task which makes us curious about its ability on this.
Can We Compress the Models?
Can we compress the large models into smaller models like we did for DistillBERT?
We will now present several works dedicated to solve these problems.
Remove Object Detector
An immediate solution for this is to directly input the entire image, however, this is not viable because of the limitation of length for Transformer input. A possible replacement for object RoI features is the final features from CNN models of the image. This is explored in a recent work called Pixel-BERT (Huang et al. (2020)) which compresses the input image with ResNet and then flatten CNN features as input tokens for Transformers. In this way, the visual feature extractor is also end-to-end trainable. This work is further extended to SOHO (Huang et al. (2021)) which uses visual dictionary embedding to sparse the input information and improve the performance.
Another interesting solution is inspired by the current ViT model. As shown in Fig.5, it breaks the image into multiple patches and then concatenate them with the word embeddings as inputs. ViLT achieves impressive inference speed with lower performance compared to SOTA models. More recently, Xue et al. (2021) uses the Swin-T as visual encoder, and it claims that this can improve the ability of extracting long range information in image. Li et al. (2021) proposed ALBEF which uses ViT as encoder. It’s also worth to note that they align the visual embedding and textual embedding with contrastive loss, which will further promote the inter-modality interaction.
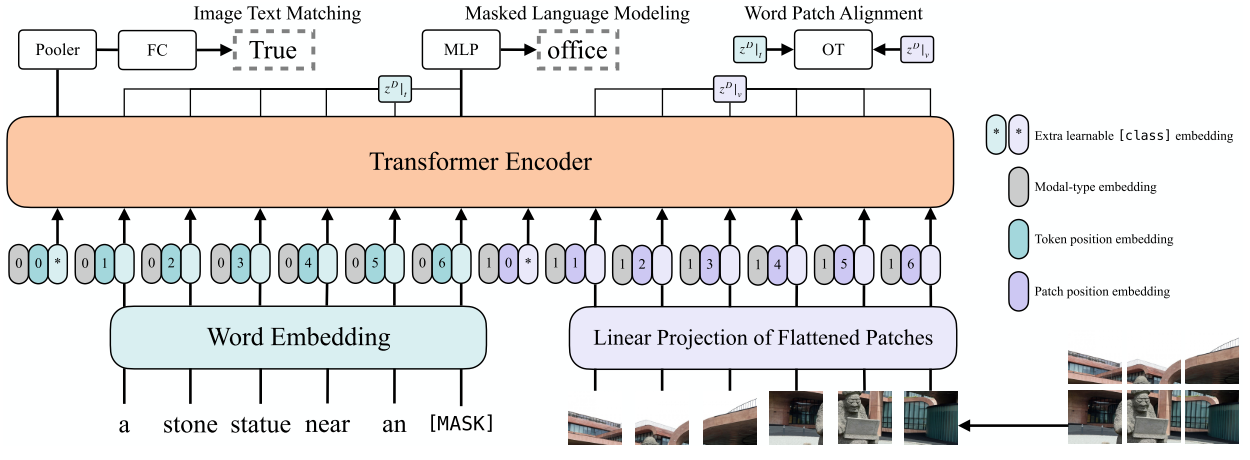
Fig.5 ViLT is proposed by Kim et al. (2021), which uses image patches as visual inputs. Finally, I also want to mention a recent work MDETR (Kamath et al. (2021)) which is inspired from the hungarian matching loss of DETR. To align with text, they use DETR to propose object queries and then they align each of them with a text span as shown in Fig.6. For example, the 4 pink bounding boxes should be aligned with the phrase “white paws”. They use the annotations from the original dataset to supervise this behavior. MDETR shows impressive performance especially on visual grounding tasks, probably because their pretraining objective is similar to this task.
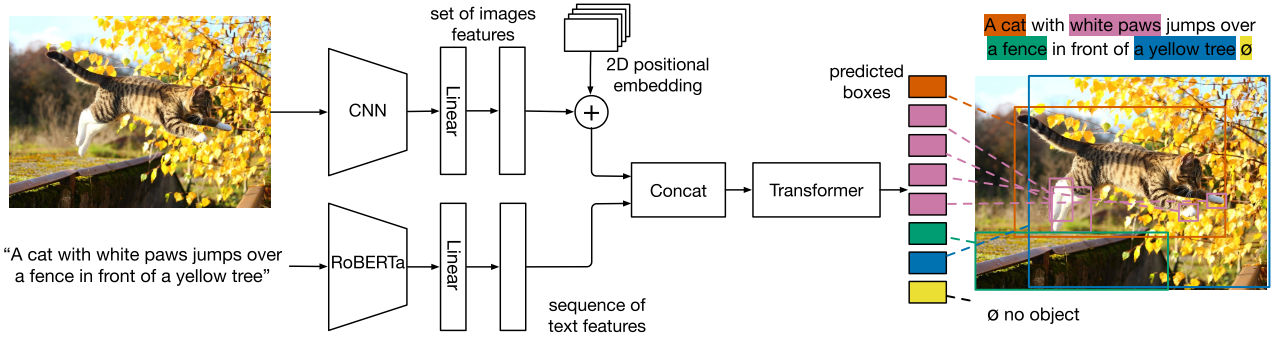
Fig.6 MDETR is proposed by Kamath et al. (2021), which outputs visual queries to align with text spans. Learn from Unpaired Image and Text
To learn from unpaired image and text in an unsupervised way, Li et al. (2021) propose to train separately from two modalities. On one hand, they use the original MLM loss to train on text alone. On the other hand, they use the concatenation of image tag and image as vision-language pair for Transformer inputs and predict masked tags and masked objects as the pretraining objective. The authors wish the model to automatically learn from two independent modalities. For example, in Fig.7, the model learn from two different representations of a cake (both in language description and in visual presentation), and it should connect these two representations together to form a concept. The results shown are promising in that they are almost the same as those trained with paired data.
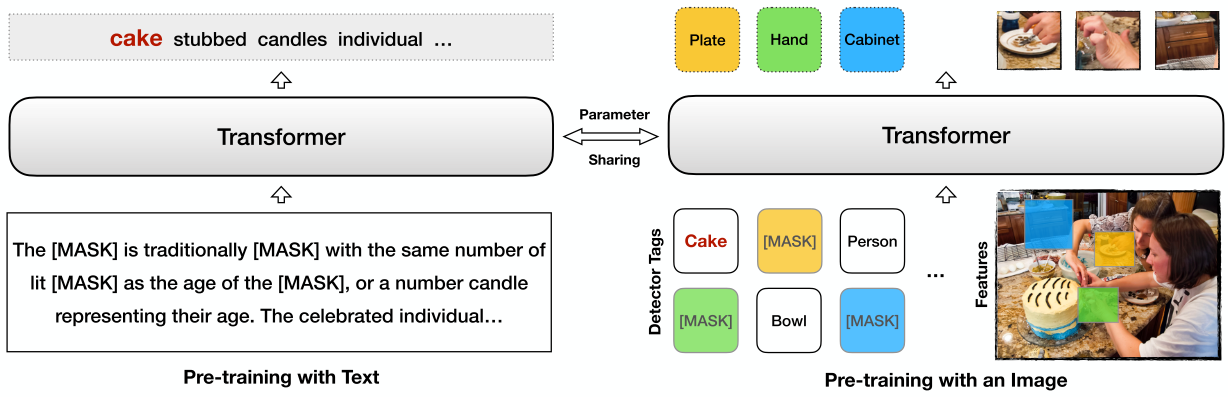
Fig.7 U-VisualBERT is proposed by Li et al. (2021), they use image tags to help the learning from unpaired image and text. Another interesting idea tries to unify the embeddings from three Transformers: for image, text and multimodal data respectively (Li et al. (2021)). It takes advantage from both paired data and unpaired data. And then, they align the embeddings with a contrastive loss as shown in Fig.8. Their experiments show that the proposed model UNIMO can outperform baselines on both multimodal tasks and NLU tasks, which shows that pretraining on unpaired data can help multimodal reasoning and pretraining on vision data can also help the learning of language.
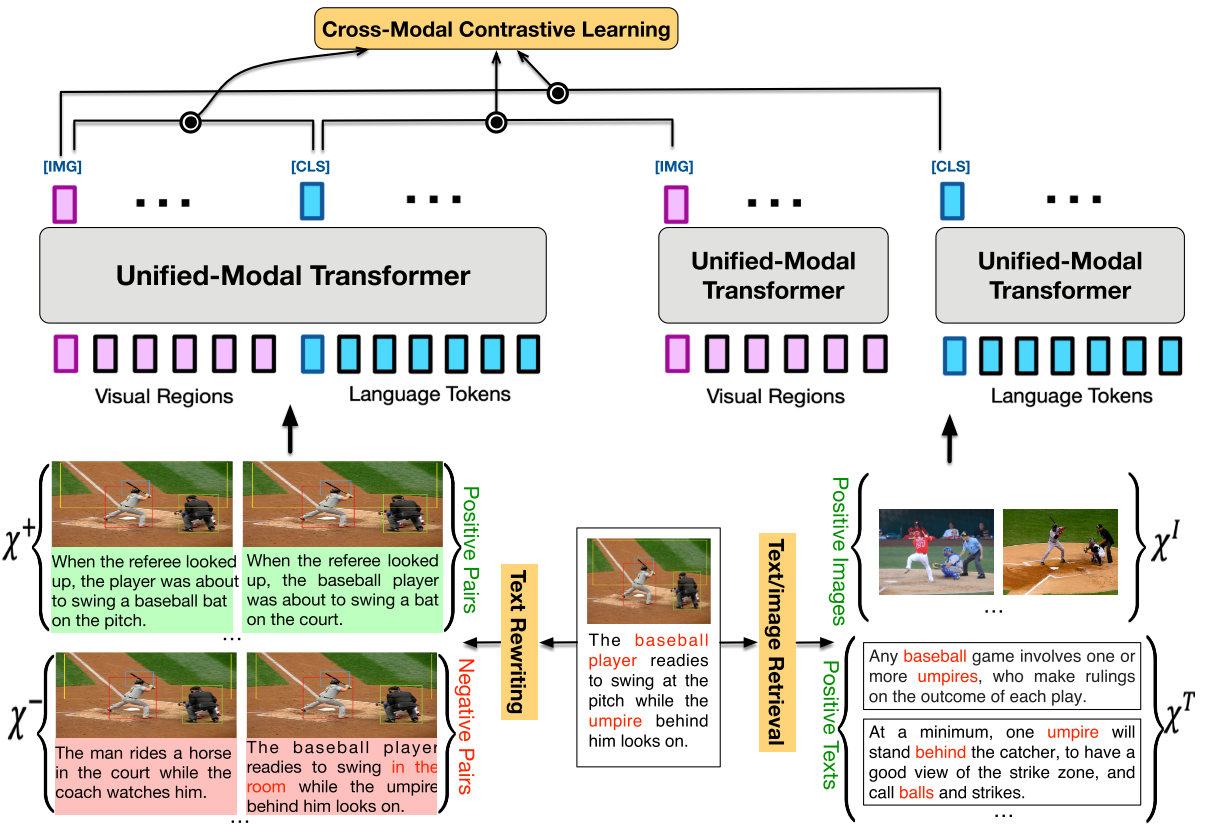
Fig.8 UNIMO is proposed by Li et al. (2021), they pretrain on both paired and unpaired data with contrastive loss. Multi-task Pretraining
Lu et al. (2019) extends ViLBERT for multi-task learning and results show that it could benefit independent tasks and at the same time save parameters linearly with respect to number of tasks.
UniT (Hu et al. (2021)) dedicates to solve both single modal and multimodal tasks with a single Transformer model. The tasks include object detection, NLI, and VQA etc.. They encode image and text features separately with two encoders, and then fuse the query feature to form the input for a unified decoder. Finally, a task-specific head is appended on top to solve different tasks independently. In this way, the model parameters are drastically reduced because we share the same model across tasks. It is worth noting that this fashion of unifying modalities into a single model and pretrain the model with multi-task objective is very popular nowadays (Likhosherstov et al. (2021), Wang et al. (2021), Li et al. (2021)).
Few/Zero-shot Finetuning
Prompt-based finetuning has shown to be effective on NLP especially for few/zero-shot scenario, given that there are no extra parameters added to the model (Gao et al. (2021)). It is simply a fill-in-the-blank task conditioned on the prompt you give to the model as shown by Fig.9.
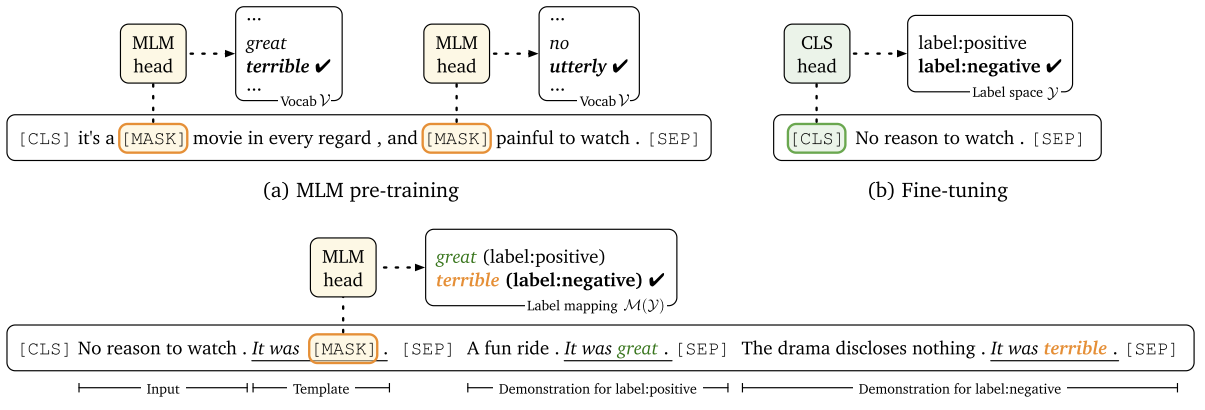
Fig.9 As shown by Gao et al. (2021), under prompt-based learning a sentiment analysis task can be formulated as filling "positive" or "negative" into the blank. This only requires the MLM head used during pretraining which closes the gap between pretraining task and finetuning task. It is recently shown that prompt-based finetuning could also work for VL Transformers. A recent prompt-based model called prefix-tuning (Li et al. (2021)) shows that a continuous prompt can also be used as an indicator for the task, where you don’t have to interpret the actual meaning of the prompt. Frozen (Tsimpoukelli et al. (2021))is ispired by this idea, and they use the image features as a dynamic continuous prompt. The prompts are dynamic in that the input image is changing for each query. And then they only finetune the vision model and fix the language model so that the knowledge learned from pretraining is preserved. As shown in Fig.10, this can be used in VQA as well as few-shot image classification. An interesting application is shown in (b) where the model is asked to answer who invent the iphone given a similar VQA triplet as an example, and the model is able to answer “Steve Jobs” with the knowledge contained in the pretrained language model.
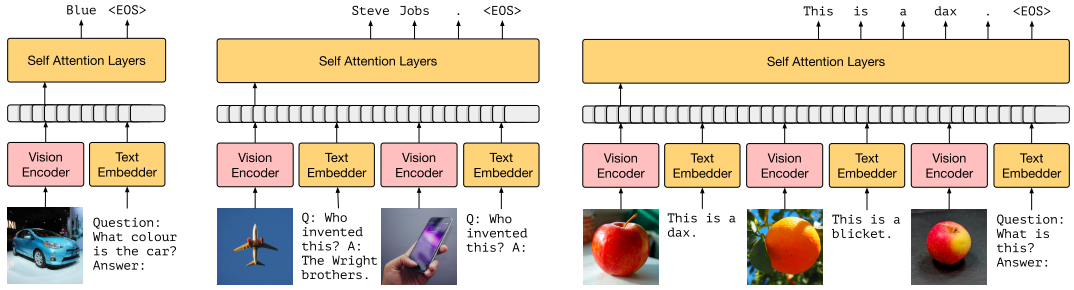
Fig.10 As shown by Tsimpoukelli et al et al. (2021), Frozen can be used in various few/zero-shot scenarios. Notice that a similar idea is shown by Cho et al. (2021). They demonstrated that several multimodal tasks can be combined into a language generation model where given a task query, the model is supposed to give an open-ended answer (Fig.11).
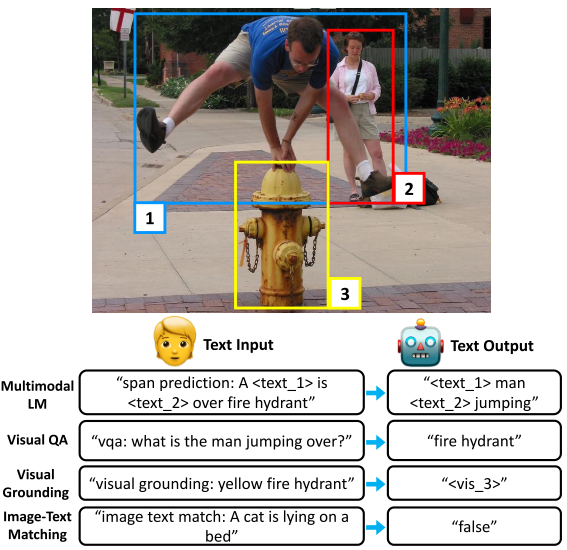
Fig.11 As shown by Cho et al et al. (2021), VL-T5 combines all the multimodal tasks into a generation task. An interesting color-prompt model is also proposed by Yao et al. (2021). They use different colored masks to cover the object regions extracted from the image, and they ask the model to answer the corresponding color for the object they are referring to (Fig.12). However, there could be color confusions, for example the model will be confused when the query is asking to find the white cat which is covered by a colored mask.
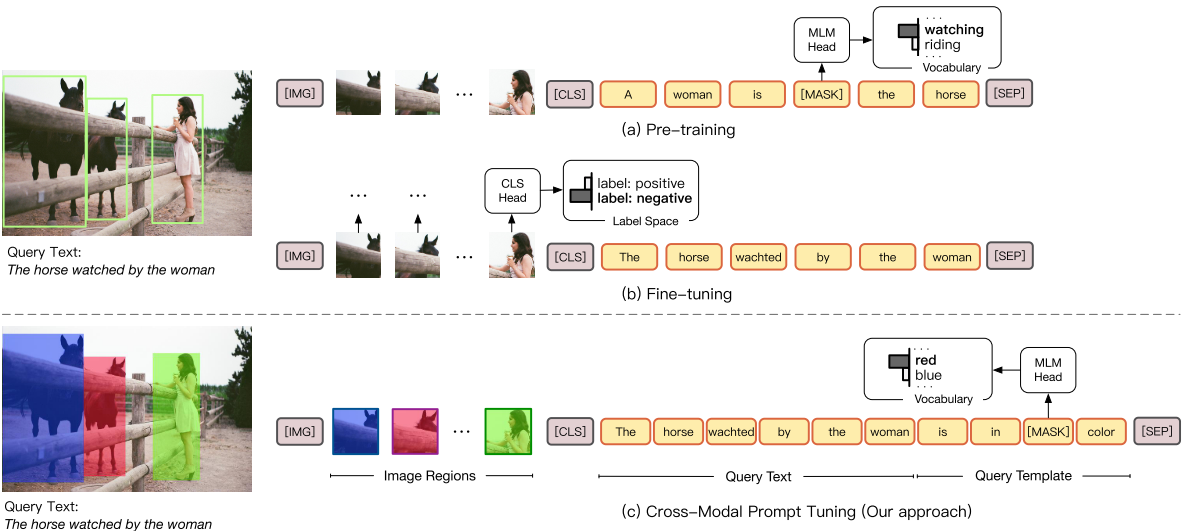
Fig.12 CPT is proposed by Yao et al et al. (2021), which uses the colors as a prompt. However, it fails to consider the color confusion when the query contains a color attribute. Image Generation with VL Transformers
As pointed out by Cho et al. (2020), when enabled to use grid features (rather than object RoIs) from CNN, LXMERT is still unable to generate meaningful images although it is trained on MRM loss. And thus they extend LXMERT into X-LXMERT which not only generates meaningful images but also preserves a good performance on discrimination tasks. They change the visual inputs to dicrete representations, and they propose to use uniform sampling during pretraining. The results are shown in Fig.13. The generated images are very blurry because of the poor generator. However, we can still see some meaningful structures. In 2021, we might have a better solution by combining CLIP and GAN.

Fig.13 Some qualitative examples generated from X-LXMERT (Cho et al et al. (2020)) Compress the Model
In DistillVLM (Fang et al. (2021)), they employed the idea of distilling knowledge from a large teacher model to a smaller student model. And they mainly resolve the challenge of object proposal inconsistency between teacher and student.
I also list papers about improving the VL pretrained Transformers in Tab.2. I will describe their novelties in short. And again, this is not a comprehensive list.
| model | year | novelty |
| 12-in-1 | 2019 | pretrain a ViLBERT with multi-task loss |
| Pixel-BERT | 2020 | use CNN feature as input |
| DeVLBERT | 2020 | mitigate dataset bias via deconfounding (intervention-based learning) |
| X-LXMERT | 2020 | extend LXMERT for image generation tasks |
| TDEN | 2021 | decoupled network + scheduled sampling to improve especially text generation |
| ViLT | 2021 | w/o CNN, improve efficiency |
| ERNIE-ViL | 2021 | introduce scene graph parsing for fine-grained cross-modal matching |
| VL-T5 | 2021 | unify all multimodal tasks w/ generation task |
| SOHO | 2021 | improve Pixel-BERT by introducing visual dictionary |
| MDETR | 2021 | inspired from DETR, w/o fixed-vocabulary |
| DistillVLM | 2021 | distill knowledge from large teacher model to smaller student model, first align RoIs |
| UniT | 2021 | unify single-modal and multi-modal with single transformer model |
| U-VisualBERT | 2021 | pretrain with unaligned image and text, feed object tag as weak supervision |
| UNIMO | 2021 | single modal help multi-modal learning, vision helps language learning. use contrastive |
| Frozen | 2021 | image embedding as prefix for text generating, well-perform on few-shot learning |
| Visual Parsing | 2021 | use Swin-T for image encoding, w/o object detector or visual dictionary, metric for inter-modality flow |
| ALBEF | 2021 | use contrastive loss to align vision and language embeddings before feeding into multi-modal encoder, ViT for image encoding, pseudo-labeling for noisy labels |
| CPT | 2021 | prompt-based tuning for V&L, coloring object regions |
| MoME | 2021 | select modal experts for different modality inputs |
[Tab.2]
Conclusion and Discussion
Starting from 2019, VL Transformers are surging multimodal community. Early discussion focus on improving pretraining by increasing size of pretraining data, designing better architectures. And recent works focus on the applicability and quality of model from the angles including removing the reliance on object detectors, learning from unpaired image-text data, more efficient finetuning as well as unifying multiple tasks and modalities into single transformers (only change the task-specific heads or even no change at all).
“Imagination is more important than knowledge – Albert Einstein”
In the future, there might be a model that can be more flexible and lightweight which can take multiple modalities as inputs just like human and doest not need too much computational cost or huamn annotations to reason between modalities.