
I am a Ph.D. student at the Halıcıoğlu Data Science Institute, UC San Diego, advised by Prof. Jingbo Shang. My research focuses on LLM post-training, continual adaptation, and memory.
I am especially interested in how language models can improve after pretraining: learning from limited task data, rare success signals, long-horizon feedback, and persistent context while retaining prior knowledge. My recent work studies knowledge injection, on-policy self-distillation / reinforcement learning, and memory-based context management.
Beyond research, I am passionate about sports, especially hiking, basketball and motor racing.
Finally, I want to express my sincere gratitude to my advisors, collaborators, and mentors for their invaluable guidance and support throughout my research and life.
Education
-
University of California San DiegoHalıcıoğlu Data Science InstitutePh.D. in Data Science2023 - present
-
University of California San DiegoElectrical EngineeringM.S. in Electrical Engineering, Machine Learning & Data Science2021 - 2023
-
Nankai UniversityPhysicsB.S. in Physics2016 - 2020
Experience
-
Google DeepMindResearch Scientist InternSummer 2026
-
Amazon Rufus (Foundation Models Team)Applied Scientist InternSummer 2025 - Spring 2026
-
AMD ResearchResearch Scientist InternSpring 2025
-
Tencent AI LabResearch Scientist InternSummer 2024
-
Amazon AWSApplied Scientist InternSummer 2023
News
Selected Publications (view all )
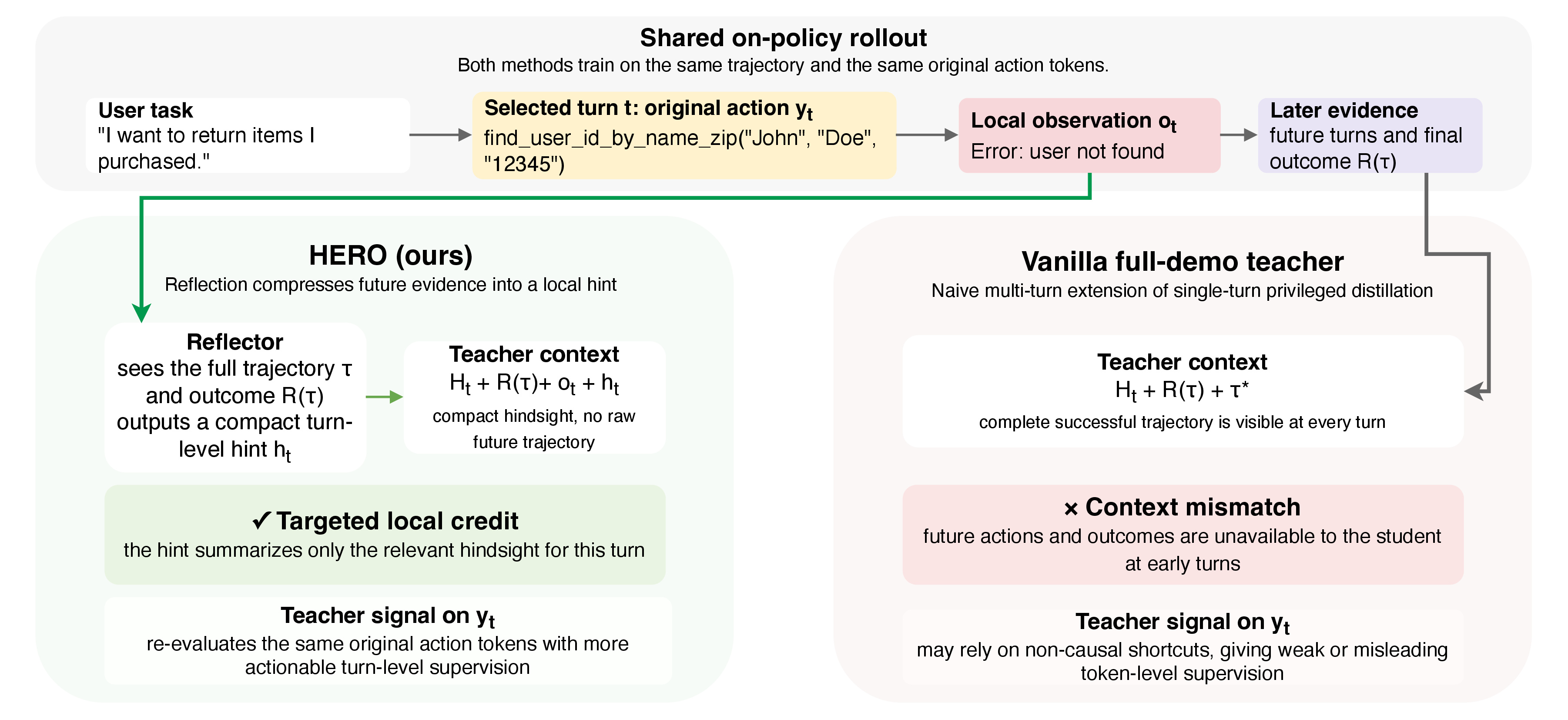
HERO: Hindsight-Enhanced Reflection from Environment Observations for Agentic Self-Distillation
Haoran Liu*, Yuwei Zhang*, Xiyao Li, Bohan Lyu, Jingbo Shang (* equal contribution)
Preprint 2026
HERO turns next environment observations into hindsight reflection signals for multi-turn agent self-distillation, improving task success and reducing unnecessary tool-use turns under limited training budgets.
HERO: Hindsight-Enhanced Reflection from Environment Observations for Agentic Self-Distillation
Haoran Liu*, Yuwei Zhang*, Xiyao Li, Bohan Lyu, Jingbo Shang (* equal contribution)
Preprint 2026
HERO turns next environment observations into hindsight reflection signals for multi-turn agent self-distillation, improving task success and reducing unnecessary tool-use turns under limited training budgets.
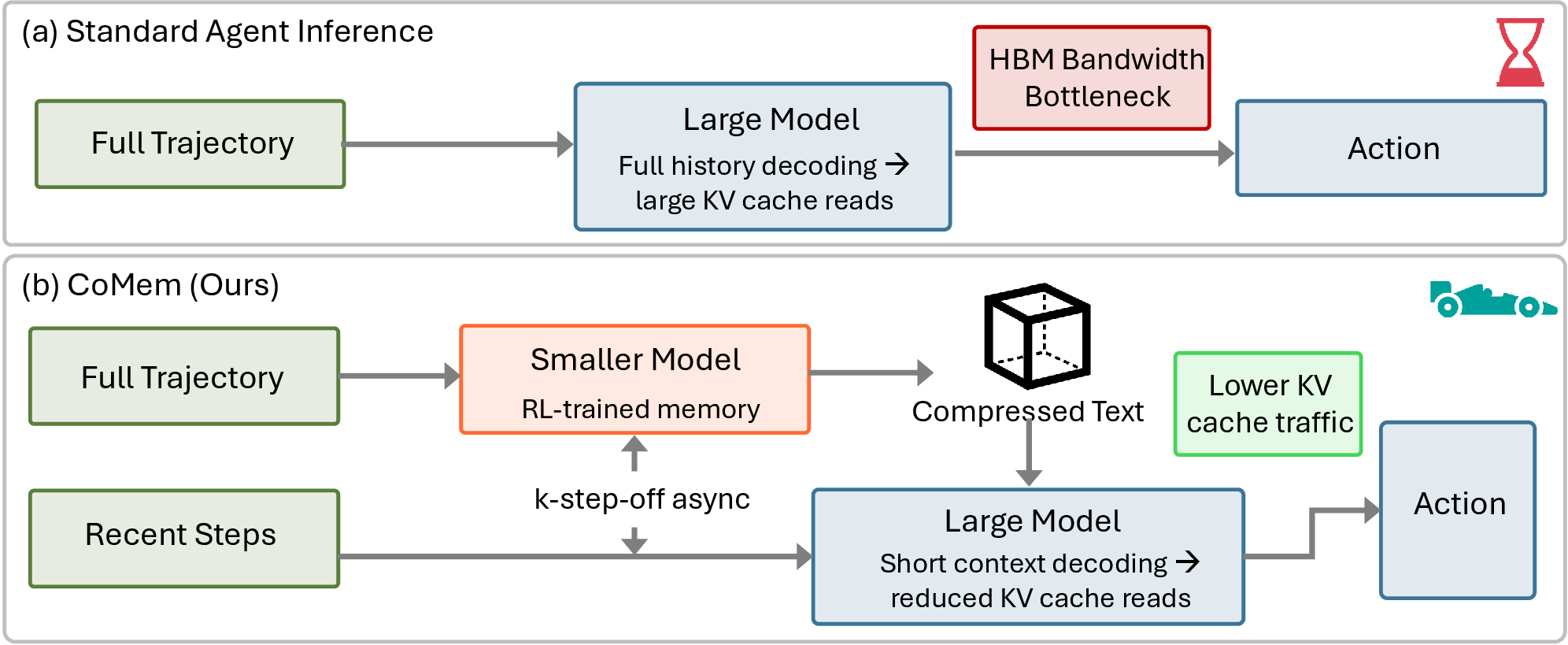
CoMem: Context Management with A Decoupled Long-Context Model
Yuwei Zhang, Chengyu Dong, Shuowei Jin, Changlong Yu, Hejie Cui, Hongye Jin, Xinyang Zhang, Hamed Bonab, Colin Lockard, Jianshu Chen, Zhenyu Shi, Jingbo Shang, Xian Li, Bing Yin
ICML 2026
CoMem decouples agent reasoning from memory summarization so long-horizon agents can preserve most long-context performance while reducing latency through asynchronous context management.
CoMem: Context Management with A Decoupled Long-Context Model
Yuwei Zhang, Chengyu Dong, Shuowei Jin, Changlong Yu, Hejie Cui, Hongye Jin, Xinyang Zhang, Hamed Bonab, Colin Lockard, Jianshu Chen, Zhenyu Shi, Jingbo Shang, Xian Li, Bing Yin
ICML 2026
CoMem decouples agent reasoning from memory summarization so long-horizon agents can preserve most long-context performance while reducing latency through asynchronous context management.
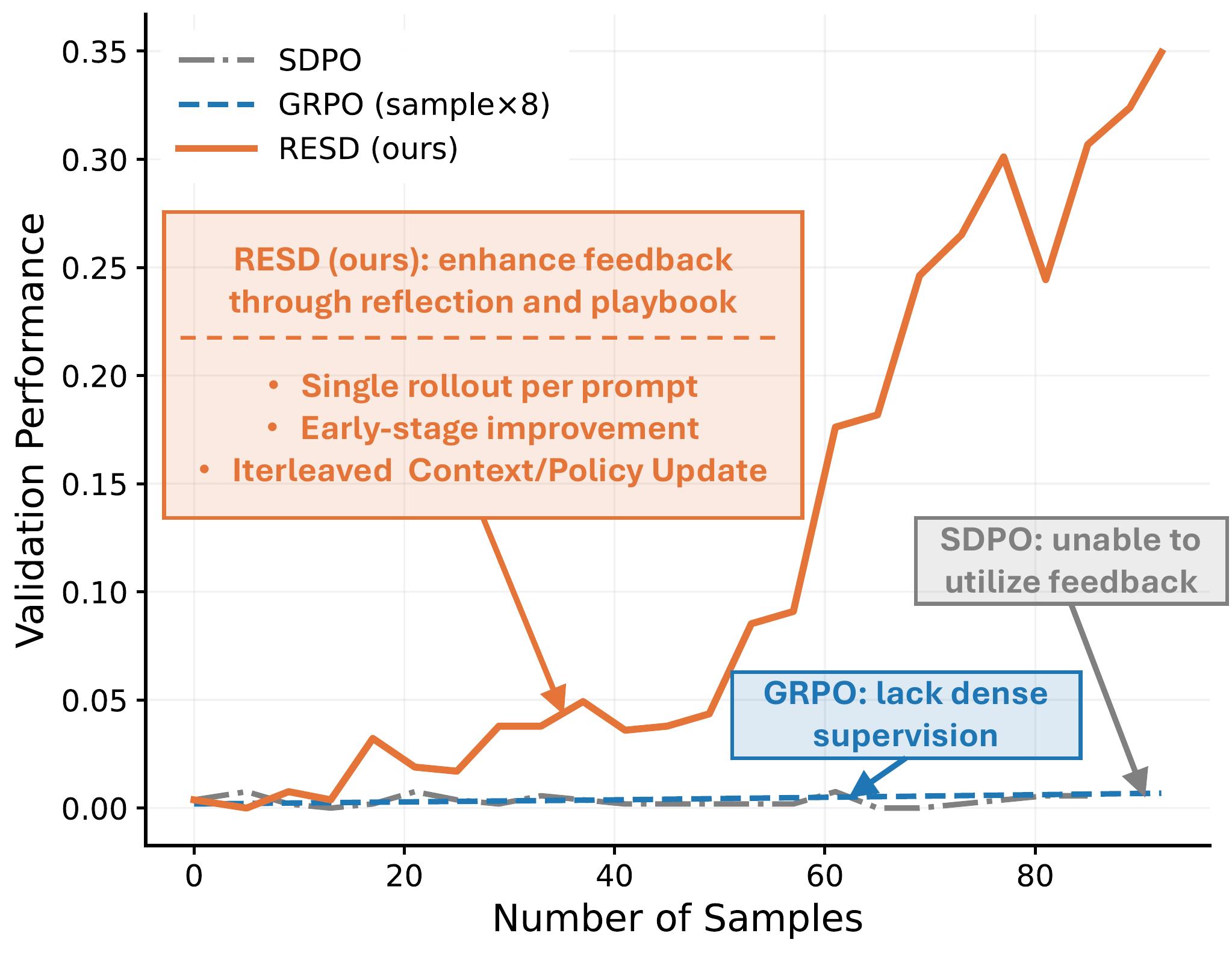
Learning with Rare Success but Rich Feedback via Reflection-Enhanced Self-Distillation
Yuwei Zhang, Sha Li, Changlong Yu, Qin Lu, Shuowei Jin, Chengyu Dong, Haoran Liu, Ilgee Hong, Xintong Li, Zhenyu Shi, Bing Yin, Jingbo Shang
Preprint 2026
RESD turns failed rollouts into reflection-based supervision and reusable playbook knowledge, letting models improve efficiently even when successful rollouts are rare.
Learning with Rare Success but Rich Feedback via Reflection-Enhanced Self-Distillation
Yuwei Zhang, Sha Li, Changlong Yu, Qin Lu, Shuowei Jin, Chengyu Dong, Haoran Liu, Ilgee Hong, Xintong Li, Zhenyu Shi, Bing Yin, Jingbo Shang
Preprint 2026
RESD turns failed rollouts into reflection-based supervision and reusable playbook knowledge, letting models improve efficiently even when successful rollouts are rare.
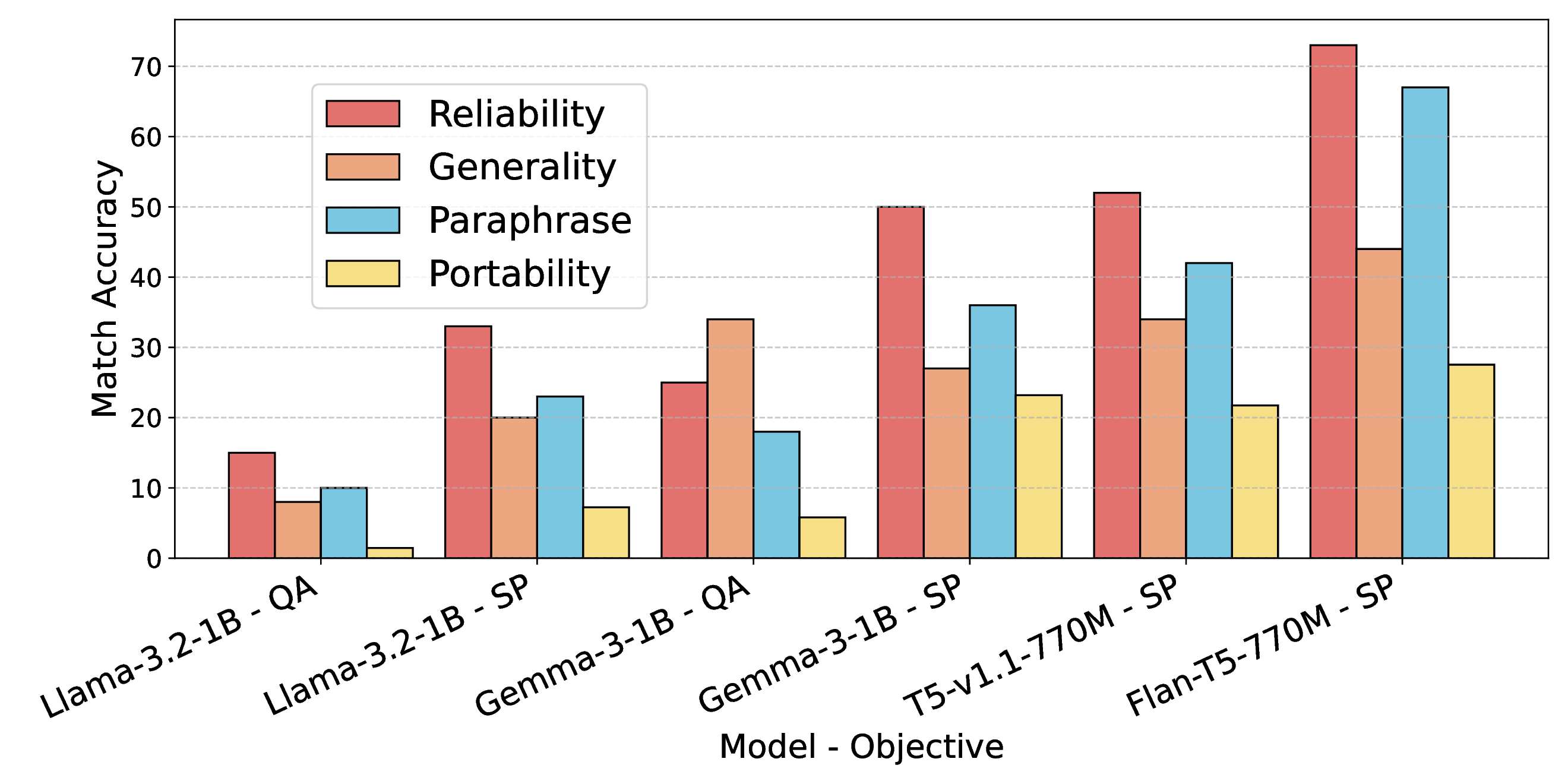
Bidirectional LMs are Better Knowledge Memorizers? A Benchmark for Real-world Knowledge Injection
Yuwei Zhang, Wenhao Yu, Shangbin Feng, Yifan Zhu, Letian Peng, Jayanth Srinivasa, Gaowen Liu, Jingbo Shang
ACL 2026 Oral
WikiDYK benchmarks real-world knowledge injection from fresh Wikipedia facts and shows bidirectional language models memorize injected knowledge more reliably than causal LMs.
Bidirectional LMs are Better Knowledge Memorizers? A Benchmark for Real-world Knowledge Injection
Yuwei Zhang, Wenhao Yu, Shangbin Feng, Yifan Zhu, Letian Peng, Jayanth Srinivasa, Gaowen Liu, Jingbo Shang
ACL 2026 Oral
WikiDYK benchmarks real-world knowledge injection from fresh Wikipedia facts and shows bidirectional language models memorize injected knowledge more reliably than causal LMs.