
New Intent Discovery
Published:
This is a blog post about the literature of discovering new intents in task-oriented dialogue systems.

Picture from https://www.analyticsinsight.net/comprehensive-guide-natural-language-processing/
New Intent Discovery for Tasked-oriented Dialogue
Backgrounds
Task-oriented Dialogue (TOD) Often works in a pipeline with each module for a different NLU task.
Intent Detection (ID) Important component in TOD system. Can be viewed as a fine-grained text classification task.
Problem Formulation
In the beginning of developing an ID model for a specific service (such as banking, healthcare and restaurant), the main challenge is to find out the most probable intents from your customers. One possible way is to cluster an existing corpus of conversations (usually collected from human-human dialogues for this service) according to the underlying intents, and then engineers could easily discover the intent from each cluster. Finding a good unsupervised clustering algorithm then becomes vital for this problem.
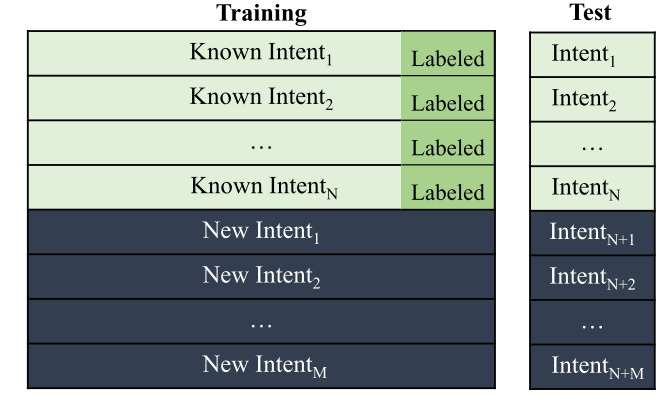
It is also worth noting that the need for new intent discovery might still exist after the development of ID model since the service is evolving all the time and new customer demands will be produced. In this case, the corpus to be clustered might contain both known and unknown intents, as shown in Fig.1. Then the algorithm is expected to distinguish the known intents while discovering new intents and the labeled data can be utilized to benefit clustering.
Difference from zero-shot learning No class information is provided during training.
Difference from out-of-scope detection/unknown intent detection Rather than simply separating unknown intents, the algorithm is needed to discriminate the semantic difference among new utterances.
Previous Methods
Early research for clustering the queries based on the user intents can be traced back to 2010 where researchers used the clustering results to develop internet search engines. Most of these research rely on user experience other than merely semantic features, such as user clicking and co-occurring searches. To name a few, Kathuria et al. (2010) simply used k-means to cluster web queries with user traits. Sadikov et al. (2010) clustered query refinements with several search results (document-click and query co-occurrences in the same search session). Hakkani-Tur et al. (2013) uses the clicked URLs as a supervision and discover new intents based on knowledge graphs. However, modern conversational ai does not have these context features which make the discussion for these research here helpless.
There exists several attempts to discover new intents without a direct usage of deep neural networks. Cheung et al. (2012) extracted feature vectors based on large knowledge base and then employed agglomerative clustering. Hakkani-Tur et al. (2015) proposed a semantic parsing based clustering method. Padmasundari et al. (2018) explored various texts representations such as word2vec, gloVe and ConceptNet, and leaded to SOTA results on public dataset at that time. A supervised clustering method was introduced in Haponchyk et al. (2018) by inferring spanning trees from a fully connected undirect graph. Later this method was modified to an end-to-end training manner with BERT as feature extractor (Haponchyk et al. (2021)).
Recent methods introduced better representation learning and improved clustering with various techniques. Shi et al. (2018) leveraged auto-encoder to assemble features and then adapts a dynamic hierarchical clustering for labeling intents. Chatterjee et al. (2020) proposed a density-based method (based on DBSCAN) to cluster corpus with features extracted from pretrained encoders. Perkins et al. (2019) observed that the context of a utterance in a dialogue between customer and agent can be utilized to infer the intent (An example can be found in Fig.2). They proposed alternating-view k-means (AV-KMEANS) to incorporate 2 views corresponding to the query and the rest of the conversation, and the experimental result with 2 kinds of encoders showed superiority over those methods that only use single view.

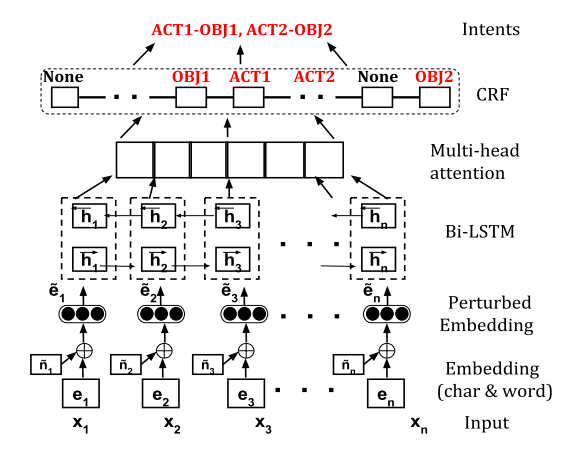
Interestingly, a generative model was proposed to directly extract open intents from the wild without any labeled examples and class information (Vedula et al. (2020)). The proposed framework OPINE is illustrated in Fig.3. OPINE interprets an intent as an action-object pair (such as reserve restaurant, book hotel, set alarm). It uses sequence tagging technique to annotate each word as either ACTION, OBJECT or NONE. Then it selects an appropriate combination of ACTION and OBJECT as an intent. This could also produce multiple intents for each query. A dataset StackExchange is collected from real-world scenario to better evaluate the model. Min et al. (2020) also proposed a similar setting called dialogue state induction as opposed to dialogue state module, which predicts dialogue states without annotated data.
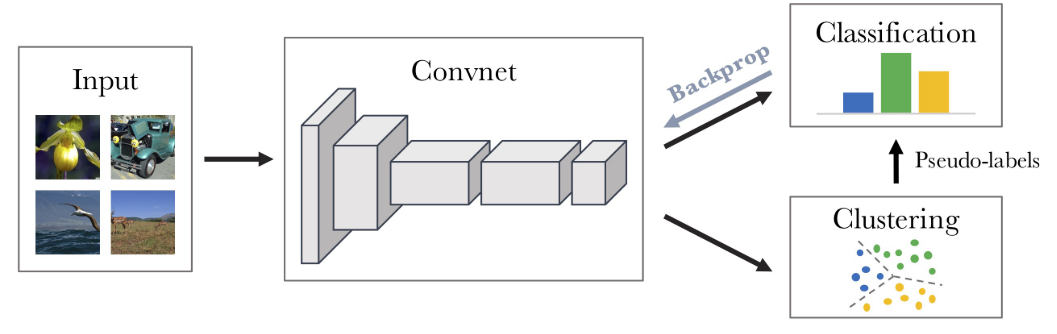
In addition, a few methods were proposed to solve semi-supervised setting as in Fig.1. Lin et al. (2019) proposed to train a model with sentence similarity task, where they used a training strategy similar to self-training to utilize labeled data. They also proposed to refine the pretrained clustering network with a clustering objective. Zhang et al. (2020) explored a popular unsupervised clustering algorithm-Deep Clustering. As shown in Fig.4, it uses k-means to find cluster centroids and assignments for each instance, then it uses produced pseudo-labels to train the network. The authors found this kind of alternative training needs to initialize a random linear layer at each iteration, so they proposed to align the clusters between current iteration and last iteration. They also uses the labeled part of the data for pretraining the network. Vedula et al (2020b) proposed to first discriminate novel intents from known intents, and then perform hierarchical clustering with transferred knowledge. It further linked discovered novel intents into domains.
Conclusion
In this post, we have discussed previous research results from early stage to the recent findings. Overall, most research lie in one of 3 settings: supervised, unsupervised and semi-supervised. They mainly explored to improve the performance from perspectives of both representation learning and clustering algorithms. Furthermore, this research area could also benefit from existing research in computer vision and natural language.